MySQL Partitioning
들어가며
서비스를 운영하다 보면 테이블에 데이터가 수천만, 수억 건씩 쌓이게 된다. 이렇게 테이블이 커지면 쿼리 성능이 떨어지고, 오래된 데이터를 정리하는 것도 쉽지 않다. 이런 상황에서 고려해볼 수 있는 것이 파티셔닝 이다.
파티셔닝이란
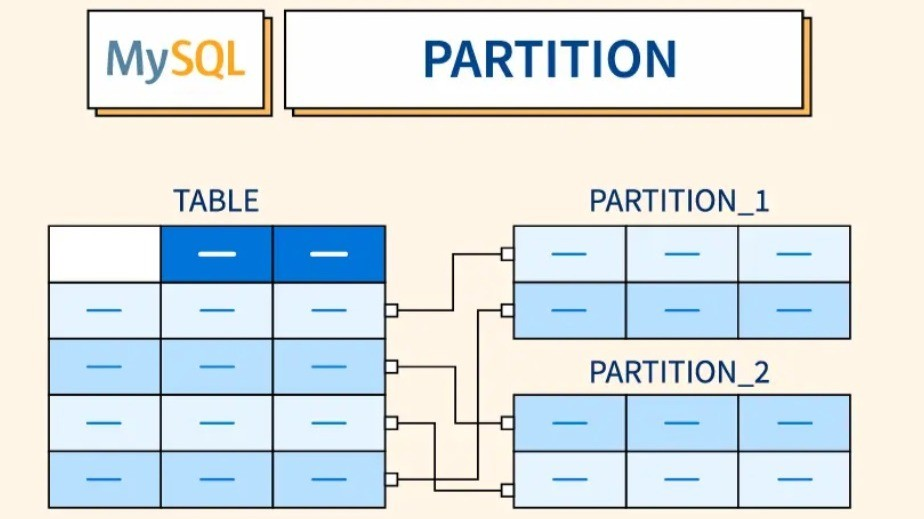
파티셔닝은 하나의 큰 테이블을 작은 단위로 나누어 관리하는 기법 이다. 논리적으로는 하나의 테이블이지만, 물리적으로는 여러 개의 파티션으로 분리되어 저장된다. 사용자 입장에서는 여전히 하나의 테이블처럼 쿼리하면 되고, MySQL이 내부적으로 적절한 파티션을 찾아서 처리해준다.
예를 들어 주문 테이블에 5년치 데이터가 쌓여있다고 하면, 대부분의 쿼리는 최근 1년 데이터만 조회하는데, 매번 5년치 전체를 스캔해야 한다면 비효율적이다. 이때 연도별로 파티셔닝을 해두면, 올해 데이터를 조회할 때 2025년 파티션만 스캔하면 된다.
왜 파티셔닝을 사용할까?
쿼리 성능 향상
파티셔닝의 가장 큰 장점은 파티션 프루닝(Partition Pruning) 이다. WHERE 절에 파티션 키가 포함되어 있으면, MySQL 옵티마이저가 필요한 파티션만 골라서 스캔한다. 나머지 파티션은 아예 건드리지 않는다.
1
2
3
4
-- created_at 컬럼 기준으로 연도별 파티셔닝된 테이블
SELECT *
FROM orders
WHERE created_at >= '2025-01-01' AND created_at < '2026-01-01';
이 쿼리는 2025년 파티션만 스캔한다. N년치 데이터가 있어도 1년치만 보면 되니까 N배 빨라지는 셈이다.
EXPLAIN PARTITIONS 명령으로 실제로 어떤 파티션이 스캔되는지 확인할 수 있다.
1
2
3
4
EXPLAIN PARTITIONS
SELECT *
FROM orders
WHERE created_at >= '2025-01-01';
주의: WHERE 절에 파티션 키가 없으면 모든 파티션을 스캔한다. 파티셔닝을 했는데 쿼리에서 파티션 키를 안 쓰면 오히려 손해다.
데이터 관리 용이
오래된 데이터를 삭제할 때 파티셔닝이 매우 효과적이다. 일반 테이블에서 1년치 데이터를 삭제하려면 DELETE 문으로 수천만 건을 지워야 한다. 시간도 오래 걸리고 그동안 락이 걸릴 수 있다.
파티셔닝된 테이블에서는 DROP PARTITION 이면 완료된다.
1
2
-- 2020년 파티션 삭제 (수천만 건이어도 즉시 완료)
ALTER TABLE orders DROP PARTITION p2020;
이게 가능한 이유는 파티션이 물리적으로 분리되어 있기 때문이다. 해당 파티션의 데이터 파일만 삭제하면 되므로 단순 DELETE 보다 훨씬 빠르다.
로그성 데이터처럼 일정 기간이 지나면 삭제해야 하는 테이블에 특히 유용하다.
수평 분할 vs 수직 분할
파티셔닝은 크게 수평 분할(Horizontal Partitioning) 과 수직 분할(Vertical Partitioning) 로 나뉜다.
수평 분할 은 행(row)을 기준으로 나누는 것이다. 같은 스키마를 가진 테이블을 여러 개로 쪼개는 방식이다. 2024년 데이터는 p2024 파티션에, 2025년 데이터는 p2025 파티션에 저장되는 식이다. MySQL의 파티셔닝이 바로 이 방식이다.
수직 분할 은 열(column)을 기준으로 나누는 것이다. 자주 조회하는 컬럼과 그렇지 않은 컬럼을 분리하거나, 민감한 정보를 별도 테이블로 분리하는 방식이다. 다만 MySQL 8.0은 수직 분할을 지원하지 않는다. 수직 분할이 필요하면 애플리케이션 레벨에서 테이블을 직접 나눠야 한다.
파티셔닝 vs 샤딩
비슷해 보이지만 다른 개념이다.
파티셔닝 은 하나의 데이터베이스 서버 안에서 테이블을 나누는 것이다. MySQL이 자체적으로 지원하고, 애플리케이션 코드를 수정할 필요가 없다.
샤딩 은 여러 데이터베이스 서버에 데이터를 분산하는 것이다. MySQL이 직접 지원하지 않아서 애플리케이션에서 “이 데이터는 어느 서버로 보낼지” 로직을 직접 구현해야 한다. 서버 간 조인도 불가능하다.
| 구분 | 파티셔닝 | 샤딩 |
|---|---|---|
| 범위 | 단일 DB 서버 내 | 여러 DB 서버 |
| 지원 | MySQL 기본 지원 | 애플리케이션 구현 필요 |
| 코드 수정 | 불필요 | 필요 |
| 확장성 | 서버 한 대 한계 | 서버 추가로 확장 |
일반적으로 파티셔닝으로 해결이 안 될 정도로 트래픽이 크면 샤딩을 고려 한다.
파티션과 인덱스
파티셔닝을 하면 인덱스도 파티션별로 분리된다. 이걸 로컬 인덱스(Local Index) 라고 한다. 각 파티션이 자체 인덱스를 가지며, 해당 파티션의 데이터만 인덱싱한다.
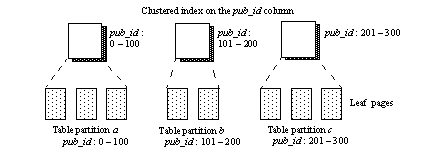
반대 개념으로 글로벌 인덱스(Global Index) 가 있다. 전체 테이블의 데이터를 하나의 인덱스로 관리하는 방식이다. 다만 MySQL은 글로벌 인덱스를 지원하지 않는다. Oracle 같은 DBMS에서는 지원하지만, MySQL은 로컬 인덱스만 사용할 수 있다.
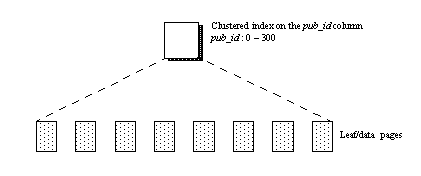
로컬 인덱스의 장점
로컬 인덱스는 파티션과 생명주기를 같이한다. 파티션을 삭제하면 해당 인덱스도 함께 삭제된다. 글로벌 인덱스였다면 파티션 삭제 후 인덱스가 깨져서 리빌딩해야 하는 상황이 생길 수 있다.
1
2
3
-- 2020년 파티션 삭제 → 해당 파티션의 인덱스도 자동 삭제
ALTER TABLE orders DROP PARTITION p2020;
-- 나머지 파티션의 인덱스는 영향 없음
주의할 점
로컬 인덱스는 파티션 단위로 분리되어 있기 때문에, 여러 파티션에 걸친 쿼리는 각 파티션의 인덱스를 따로 타야 한다. 파티션 프루닝이 제대로 동작하지 않으면 오히려 성능이 나빠질 수 있다.
또한 MySQL의 제약사항에 따라 PK나 UNIQUE 인덱스에는 반드시 파티션 키가 포함되어야 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-- 잘못된 예: 파티션 키(created_at)가 PK에 없음
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
created_at DATE,
...
) PARTITION BY RANGE (YEAR(created_at)) (...);
-- 올바른 예: 파티션 키를 PK에 포함
CREATE TABLE orders (
id BIGINT,
created_at DATE,
PRIMARY KEY (id, created_at)
) PARTITION BY RANGE (YEAR(created_at)) (...);
파티션 키 설계
파티션 키를 잘못 정하면 파티셔닝의 이점을 전혀 누리지 못한다. 한번 정하면 바꾸기도 어려우니 신중하게 선택해야 한다.
GOOD 파티션 키
1. 쿼리 패턴에 맞는 컬럼을 선택한다.
WHERE 절에 자주 등장하는 컬럼이어야 파티션 프루닝이 동작한다. 주문 테이블이라면 주문일자, 로그 테이블이라면 로그 생성일이 좋은 후보다.
2. 데이터가 고르게 분포되는 컬럼을 선택한다.
특정 파티션에만 데이터가 몰리면 그 파티션이 병목이 된다.
BAD 파티션 키
1. UUID나 랜덤 값은 피한다.
HASH 파티셔닝에서 분포는 고를 수 있지만, 범위 검색이 불가능하고 파티션 프루닝도 어렵다.
2. 자주 업데이트되는 컬럼은 피한다.
파티션 키가 바뀌면 데이터가 다른 파티션으로 이동해야 하는데, 이건 DELETE + INSERT와 같아서 비용이 크다.
3. NULL 값이 많은 컬럼은 피한다.
NULL 처리 방식이 파티션 타입마다 다르고 예상치 못한 동작을 할 수 있다.
파티셔닝의 제한사항
MySQL 파티셔닝에는 몇 가지 제약이 있다. 도입 전에 반드시 확인해야 한다.
-
Foreign Key를 사용할 수 없다. 파티션 테이블은 FK를 참조하거나 참조될 수 없다. FK가 필요한 테이블이라면 파티셔닝을 포기하거나 애플리케이션 레벨에서 무결성을 관리해야 한다.
-
Full-Text 인덱스를 사용할 수 없다. 전문 검색이 필요한 테이블은 파티셔닝하면 안 된다.
-
공간 데이터 타입(Point, Geometry 등)을 사용할 수 없다. 공간 검색이 필요한 테이블도 파티셔닝 대상에서 제외된다.
-
PK와 UNIQUE 인덱스에 파티션 키가 포함되어야 한다. 앞서 언급한 것처럼, 파티션 키 없이는 유니크 제약을 보장할 수 없기 때문이다.
-
파티션 개수는 1000개 미만을 권장한다. 너무 많은 파티션은 메타데이터 관리 오버헤드가 커진다.
그 외에도 자세한 사항들은 이 글 맨 하단의 Reference 에서 공식문서를 참고해보자.
언제 파티셔닝을 쓰면 안 될까?
파티셔닝이 만능은 아니다. 다음 상황에서는 오히려 독이 될 수 있다.
1. 데이터가 충분히 적을 때.
수백만 건 이하라면 인덱스만 잘 걸어도 충분하다. 파티셔닝은 관리 복잡도를 높이니까 필요 없으면 안 하는 게 낫다.
2. 쿼리에서 파티션 키를 안 쓸 때.
파티션 프루닝이 동작하지 않으면 모든 파티션을 스캔해야 해서 오히려 느려진다.
3. FK나 Full-Text 검색이 필요할 때.
제한사항에 걸리면 설계를 다시 해야 한다.
파티셔닝을 도입하기 전에
EXPLAIN PARTITIONS로 실제 쿼리가 파티션 프루닝을 타는지 반드시 확인하자.
마치며
파티셔닝은 대용량 테이블을 효율적으로 관리하기 위한 강력한 도구다. 특히 파티션 프루닝 을 통한 쿼리 성능 향상과, DROP PARTITION 을 통한 빠른 데이터 삭제가 핵심 장점이다.
다만 제약사항이 꽤 있고, 잘못 설계하면 오히려 성능이 나빠질 수 있다. 파티션 키 선택이 가장 중요하며, 쿼리 패턴을 충분히 분석한 후에 도입해야 한다.
데이터가 수천만 건을 넘어가고, 특정 범위의 데이터만 주로 조회하며, 오래된 데이터를 주기적으로 삭제해야 하는 상황이라면 파티셔닝을 적극 검토해볼 만하다.
파티셔닝의 종류도 다양하기 때문에 추가로 알아보고 직접 비교해보며 적용해보는 것이 좋을 것 같다.